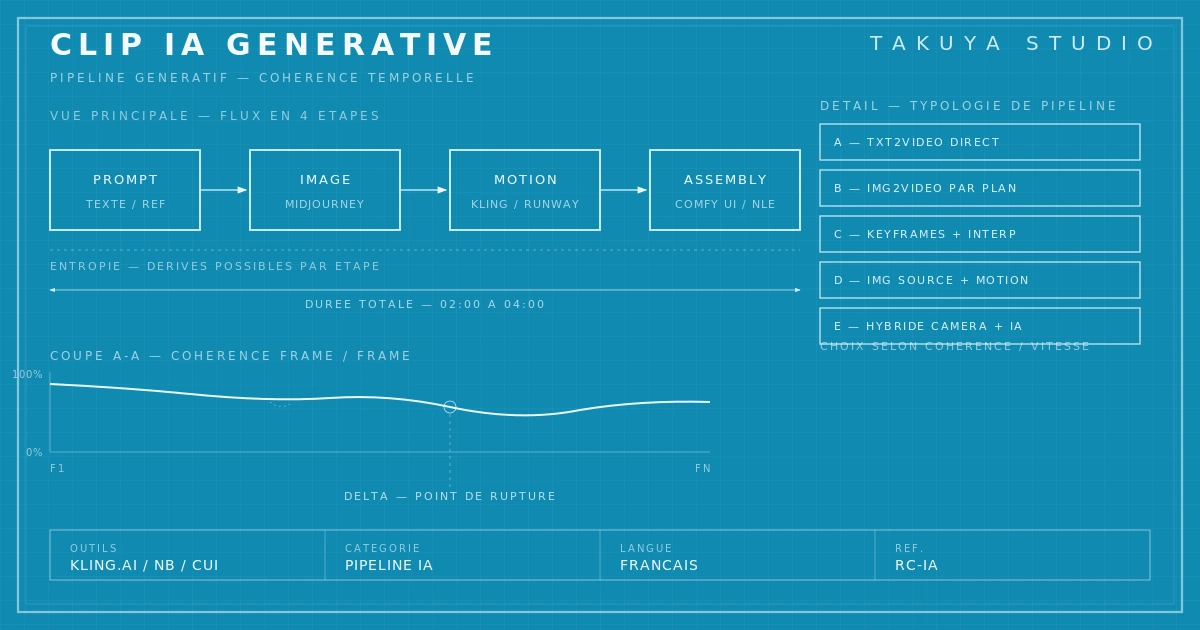
Pipeline 2026 — quatre outils, une chaîne instable
L'IA générative appliquée au clip musical s'est stabilisée, en 2026, autour d'une chaîne d'outils relativement bien identifiée. La génération d'images sources passe le plus souvent par Midjourney, qui tient l'écart stylistique d'un univers entier sur des centaines de plans, et par Nano Banana lorsqu'il faut produire des variations rapides autour d'un prompt déjà éprouvé. La mise en mouvement utilise majoritairement Kling.ai, dont les modèles vidéo offrent à ce jour la continuité de personnage la plus convaincante du marché. L'assemblage et les retouches frame par frame se font dans ComfyUI, un environnement de programmation visuelle qui permet de chaîner plusieurs modèles open source et d'écrire des workflows reproductibles d'un projet à l'autre.
Cette quadrupartie n'a rien d'une recette. Les trois premiers maillons sont propriétaires, mis à jour de façon imprévisible, parfois cassés du jour au lendemain par une nouvelle version qui change leurs priors esthétiques. Le quatrième est libre mais demande des compétences proches de celles d'un développeur. La chaîne est l'épine dorsale ; le travail réel se passe entre ses vertèbres, dans les heures de tri et de correction qu'aucune démonstration commerciale ne montre jamais. Plus que d'un pipeline, il faudrait parler d'une grammaire instable, à apprendre puis à désapprendre tous les six mois.
La cohérence temporelle, ou l'art du raccord invisible
Le défaut historique des modèles de génération vidéo est ce que les anglophones appellent flicker : un papillonnement où chaque image se permet une légère divergence par rapport à la précédente. Un cheveu qui change de longueur, un grain de peau qui se déplace, un fond qui respire malgré lui, un vêtement qui altère sa coupe entre deux frames. La presse spécialisée a documenté ces premiers pas vacillants : Le Monde décrit comment l'irruption de la vidéo générée a redessiné les contours du métier de l'image en quelques mois, sans pour autant lisser ses défauts d'enfance. La cohérence temporelle est le seuil au-delà duquel un clip IA cesse d'être une expérience de laboratoire pour devenir une œuvre tenable.
Plusieurs leviers permettent de la construire. Les keyframes ancrées par image source maintiennent l'identité d'un personnage à travers les transitions. Le contrôle des seeds entre plans permet de faire revenir un même univers visuel à plusieurs moments du morceau. La post-production assume sa part — stabilisation, étalonnage commun, masquage des dérives résiduelles, et parfois choix délibéré d'un défaut conservé qui devient esthétique plutôt qu'erreur. Les modèles vidéo récents ont rendu cette discipline beaucoup plus accessible qu'elle ne l'était il y a deux ans, sans pour autant la rendre automatique. La continuité reste une intention humaine, pas une fonction du logiciel — la page consacrée au flicker, au drift et aux méthodes 2026 détaille les techniques précises de stabilisation.
Le rapport au temps — l'IA n'accélère rien, elle déplace
Le malentendu qui circule autour de l'IA générative tient en une phrase : on croit qu'elle accélère le travail. Elle ne fait, en pratique, que déplacer le temps. Là où un tournage classique demande des repérages, un casting, un budget logistique et trois jours de plateau, un clip 100 % IA exige des centaines de générations triées, des passes correctives, des montages-tests, des journées entières de prompts ajustés au pixel près. Le rapport entre ce qui sort d'un modèle et ce qui mérite d'être conservé varie typiquement entre un sur dix et un sur cinquante. Aucune de ces étapes ne s'externalise.
Une comparaison juste se mesure en heures de travail visible et invisible, pas en jours de calendrier ni en lignes de facture. Camus écrivait que ce qui distingue le créateur du faiseur est qu'il refuse les facilités. Le faiseur d'IA produit en cinq minutes ; le créateur d'IA jette quarante-neuf images sur cinquante. La différence n'est pas une affaire d'outil — elle est une affaire d'exigence, et cette exigence ne s'achète pas plus aujourd'hui qu'hier. C'est dans ce repli que se loge encore, en 2026, la pratique professionnelle de la réalisation de clip : un terrain où l'IA cohabite avec les outils standards du métier, sans prétendre les remplacer.
La question de la direction — qui dirige, avec quelle culture ?
Un modèle de diffusion latente livré à lui-même produit toujours la même chose : la moyenne culturelle des images sur lesquelles il a été entraîné. Visages lisses, lumière douce, composition centrée, palette dérivant vers les bleus et les ors. Ce n'est ni vilain ni laid — c'est simplement déjà vu, mille fois. C'est l'accent neutre des modèles, le résultat d'une pondération statistique sur quelques milliards d'images publiques. La question pertinente n'est plus « que peut faire l'IA ? » — elle peut beaucoup, et le démontre tous les jours. La question pertinente est « qui la dirige, avec quelle culture, vers quelle vision ? ».
La singularité visuelle, dans le clip IA, ne se trouve pas dans la machine — elle se construit contre elle, par contraste, par décalage. Un cadre serré inhabituel, un défaut conservé, une référence inattendue glissée dans le prompt, une post-production qui éloigne sciemment du résultat brut. Cette discipline est cousine de celle qui régit la pochette d'album, le générique de film ou la photographie d'auteur : un parti pris formel précède toujours l'outil. La technique sert un regard, jamais l'inverse. Un clip qui ressemble à mille autres clips IA n'est pas un échec technique — c'est un échec de direction artistique. Aucun pipeline ne corrige ce manque-là, et aucune mise à jour de modèle ne le corrigera demain. Il faudra toujours quelqu'un dans la pièce pour décider ce qu'on garde et ce qu'on jette.