Le défaut central des modèles vidéo génératifs — celui qui empêche depuis 2022 le clip 100 % IA de tenir sur une durée éditoriale — porte un nom anglais : flicker. Il désigne le papillonnement involontaire qui apparaît lorsqu'un modèle de diffusion génère chaque frame en s'autorisant une légère dérive par rapport à la précédente. Un cheveu qui change de longueur, un grain de peau qui se déplace, un fond qui respire malgré lui, un vêtement qui altère sa coupe entre deux images. Cette page développe ce que la Clip et IA générative — état des lieux 2026 désigne comme le problème de la cohérence dans le clip généré, et propose un état des méthodes pour le contenir en 2026, sans en faire pour autant un problème résolu.
Pourquoi les modèles dérivent — la nature du flicker
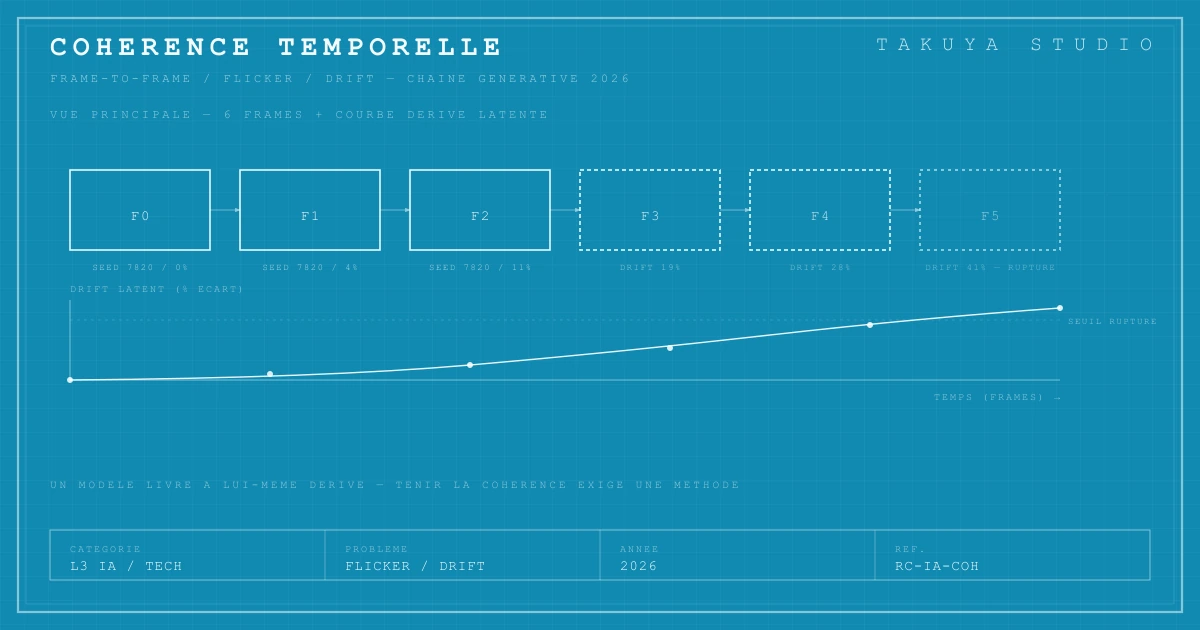
Un modèle de diffusion latente ne « comprend » pas un sujet : il en produit, à chaque frame, un échantillon statistique compatible avec le prompt. Deux frames adjacentes générées indépendamment, même avec le même prompt et le même seed, divergent légèrement parce que le bruit injecté en entrée du processus de diffusion n'est jamais exactement reproduit. Les modèles vidéo récents — AnimateDiff, Kling, Hailuo, Sora — ajoutent une condition temporelle pour rendre les frames adjacentes mutuellement cohérentes, mais cette condition n'est qu'un guide statistique : elle n'élimine pas la dérive, elle l'atténue. Sur des séquences courtes (1 à 3 secondes), la cohérence est excellente. Au-delà de 5 secondes, la dérive s'accumule et devient lisible — la chercheuse Andreas Blattmann documente ce phénomène dans le papier fondateur d'AnimateDiff en 2023, montrant comment l'écart latent entre la frame initiale et la frame N croît de façon monotone.
Le drift des seeds sur les longues séquences
Le second pli du problème est plus pernicieux. Sur un clip de 3 minutes, on n'a pas un plan continu : on a vingt à cinquante plans courts, chacun généré séparément, parfois avec des prompts adjacents mais distincts. Chaque plan repose sur un seed (la graine aléatoire qui détermine le bruit initial du processus de diffusion). Si les seeds sont laissés au hasard, l'identité d'un personnage, son éclairage, la palette du décor dérivent d'un plan à l'autre. Le visage du chanteur change de structure entre le couplet et le refrain ; la veste rouge du début vire à l'orange à la moitié du clip ; le grain photographique passe d'argentique imité à numérique lisse sans qu'on ait demandé quoi que ce soit. Ce drift de seeds — distinct du flicker frame-à-frame — est ce qui sépare une démo virale de trente secondes d'un clip qui tient trois minutes sans qu'on perde son sujet.
Les méthodes 2026 pour contenir la dérive
Plusieurs leviers existent, aucun ne suffit seul. La méthode la plus solide reste l'img2img frame-to-frame : on génère une image source maîtrisée (Midjourney, retouche manuelle), puis on l'utilise comme conditionnement de chaque frame de la séquence. La dérive est contenue parce qu'elle est arrimée à un point fixe externe au modèle. C'est laborieux — il faut une image source par groupe de plans cohérents — mais c'est ce qui produit aujourd'hui les clips IA les plus tenus visuellement. AnimateDiff, plug-in d'animation pour les modèles Stable Diffusion, ajoute une couche temporelle pré-entraînée qui rend les frames mutuellement conscientes ; il est devenu le standard open source pour les séquences de 16 à 64 frames. Les modèles propriétaires Kling, Hailuo et Sora ont popularisé en 2024-2025 le conditionnement par image de référence : on fournit une frame source, le modèle l'anime en tenant l'identité du sujet sur 5 à 10 secondes. Pour les workflows complexes, ComfyUI permet de chaîner plusieurs modèles, de fixer les seeds, de réinjecter des frames intermédiaires comme conditions — chaque studio sérieux maintient ses propres workflows reproductibles d'un projet à l'autre.
La post-production assume sa part
Aucune méthode générative ne supprime le flicker complètement. Une partie du travail se passe donc après la génération, sur le banc de montage. Stabilisation optique dans After Effects ou DaVinci pour lisser les micro-mouvements parasites. Étalonnage commun appliqué à toutes les séquences pour unifier la palette, indépendamment du modèle qui les a produites. Masques de rotoscopie sur les zones les plus instables, parfois reliés à des zones IA-générées encore plus stables (un fond statique remplaçant un fond qui dérive). Choix esthétique du défaut, enfin : un flicker conservé à dessein, transformé en grain expressif, peut devenir signature visuelle plutôt qu'erreur — c'est la stratégie de plusieurs clips récents qui assument leur origine générative au lieu de tenter de la masquer.
Ce que cela change pour qui dirige le clip
La cohérence temporelle, en 2026, n'est plus une fonction du logiciel : elle est une discipline de plateau. Elle se prépare avant la génération (image source, choix des seeds, segmentation des plans), elle se vérifie pendant (revue frame-à-frame des sorties, tri 1 sur 10 ou 1 sur 50), elle se corrige après (post-production active). C'est en cela qu'un clip 100 % IA bien tenu coûte autant de temps qu'un tournage classique : la part automatisée est la génération elle-même, qui occupe peut-être 5 % du temps total ; les 95 % restants sont des heures humaines de tri, de raccord, de correction. Cette répartition n'apparaît dans aucune démonstration commerciale. Elle est pourtant la condition pour qu'un modèle livré à lui-même cesse de produire la moyenne culturelle de ses données d'entraînement — et redevienne l'outil d'une intention.